Note
Click here to download the full example code
Compare outer optimizers¶
This example shows how to perform hyperparameter optimization for sparse logistic regression using a held-out test set.
# Authors: Quentin Bertrand <quentin.bertrand@inria.fr>
# Quentin Klopfenstein <quentin.klopfenstein@u-bourgogne.fr>
# Mathurin Massias
#
# License: BSD (3-clause)
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from celer import LogisticRegression
from libsvmdata.datasets import fetch_libsvm
from sparse_ho import ImplicitForward
from sparse_ho.ho import grad_search
from sparse_ho.utils import Monitor
from sparse_ho.models import SparseLogreg
from sparse_ho.criterion import HeldOutLogistic
from sparse_ho.utils_plot import discrete_cmap
from sparse_ho.grid_search import grid_search
from sparse_ho.optimizers import LineSearch, GradientDescent, Adam
print(__doc__)
dataset = 'rcv1.binary'
# dataset = 'simu'
if dataset != 'simu':
X, y = fetch_libsvm(dataset)
X = X[:, :100]
else:
X, y = make_classification(
n_samples=100, n_features=1_000, random_state=42, flip_y=0.02)
n_samples = X.shape[0]
idx_train = np.arange(0, n_samples // 2)
idx_val = np.arange(n_samples // 2, n_samples)
n_samples = len(y[idx_train])
alpha_max = np.max(np.abs(X[idx_train, :].T @ y[idx_train]))
alpha_max /= 2 * len(idx_train)
alpha_max = alpha_max
alpha_min = alpha_max / 100
max_iter = 100
tol = 1e-8
n_alphas = 30
p_alphas = np.geomspace(1, 0.0001, n_alphas)
alphas = alpha_max * p_alphas
Out:
/home/circleci/miniconda3/lib/python3.9/site-packages/seaborn/cm.py:1582: UserWarning: Trying to register the cmap 'rocket' which already exists.
mpl_cm.register_cmap(_name, _cmap)
/home/circleci/miniconda3/lib/python3.9/site-packages/seaborn/cm.py:1583: UserWarning: Trying to register the cmap 'rocket_r' which already exists.
mpl_cm.register_cmap(_name + "_r", _cmap_r)
/home/circleci/miniconda3/lib/python3.9/site-packages/seaborn/cm.py:1582: UserWarning: Trying to register the cmap 'mako' which already exists.
mpl_cm.register_cmap(_name, _cmap)
/home/circleci/miniconda3/lib/python3.9/site-packages/seaborn/cm.py:1583: UserWarning: Trying to register the cmap 'mako_r' which already exists.
mpl_cm.register_cmap(_name + "_r", _cmap_r)
/home/circleci/miniconda3/lib/python3.9/site-packages/seaborn/cm.py:1582: UserWarning: Trying to register the cmap 'icefire' which already exists.
mpl_cm.register_cmap(_name, _cmap)
/home/circleci/miniconda3/lib/python3.9/site-packages/seaborn/cm.py:1583: UserWarning: Trying to register the cmap 'icefire_r' which already exists.
mpl_cm.register_cmap(_name + "_r", _cmap_r)
/home/circleci/miniconda3/lib/python3.9/site-packages/seaborn/cm.py:1582: UserWarning: Trying to register the cmap 'vlag' which already exists.
mpl_cm.register_cmap(_name, _cmap)
/home/circleci/miniconda3/lib/python3.9/site-packages/seaborn/cm.py:1583: UserWarning: Trying to register the cmap 'vlag_r' which already exists.
mpl_cm.register_cmap(_name + "_r", _cmap_r)
/home/circleci/miniconda3/lib/python3.9/site-packages/seaborn/cm.py:1582: UserWarning: Trying to register the cmap 'flare' which already exists.
mpl_cm.register_cmap(_name, _cmap)
/home/circleci/miniconda3/lib/python3.9/site-packages/seaborn/cm.py:1583: UserWarning: Trying to register the cmap 'flare_r' which already exists.
mpl_cm.register_cmap(_name + "_r", _cmap_r)
/home/circleci/miniconda3/lib/python3.9/site-packages/seaborn/cm.py:1582: UserWarning: Trying to register the cmap 'crest' which already exists.
mpl_cm.register_cmap(_name, _cmap)
/home/circleci/miniconda3/lib/python3.9/site-packages/seaborn/cm.py:1583: UserWarning: Trying to register the cmap 'crest_r' which already exists.
mpl_cm.register_cmap(_name + "_r", _cmap_r)
Dataset: rcv1.binary
Grid-search¶
estimator = LogisticRegression(
penalty='l1', fit_intercept=False, max_iter=max_iter)
model = SparseLogreg(estimator=estimator)
criterion = HeldOutLogistic(idx_train, idx_val)
monitor_grid = Monitor()
grid_search(
criterion, model, X, y, alpha_min, alpha_max,
monitor_grid, alphas=alphas, tol=tol)
objs = np.array(monitor_grid.objs)
Out:
Iteration 1 / 30
Iteration 2 / 30
Iteration 3 / 30
Iteration 4 / 30
Iteration 5 / 30
Iteration 6 / 30
Iteration 7 / 30
Iteration 8 / 30
Iteration 9 / 30
Iteration 10 / 30
Iteration 11 / 30
Iteration 12 / 30
Iteration 13 / 30
Iteration 14 / 30
Iteration 15 / 30
Iteration 16 / 30
Iteration 17 / 30
Iteration 18 / 30
Iteration 19 / 30
Iteration 20 / 30
Iteration 21 / 30
Iteration 22 / 30
Iteration 23 / 30
Iteration 24 / 30
Iteration 25 / 30
Iteration 26 / 30
Iteration 27 / 30
Iteration 28 / 30
Iteration 29 / 30
Iteration 30 / 30
Grad-search¶
optimizer_names = ['line-search', 'gradient-descent', 'adam']
optimizers = {
'line-search': LineSearch(n_outer=10, tol=tol),
'gradient-descent': GradientDescent(n_outer=10, step_size=100),
'adam': Adam(n_outer=10, lr=0.11)}
monitors = {}
alpha0 = alpha_max / 10 # starting point
for optimizer_name in optimizer_names:
estimator = LogisticRegression(
penalty='l1', fit_intercept=False, solver='saga', tol=tol)
model = SparseLogreg(estimator=estimator)
criterion = HeldOutLogistic(idx_train, idx_val)
monitor_grad = Monitor()
algo = ImplicitForward(tol_jac=tol, n_iter_jac=1000)
optimizer = optimizers[optimizer_name]
grad_search(
algo, criterion, model, optimizer, X, y, alpha0,
monitor_grad)
monitors[optimizer_name] = monitor_grad
current_palette = sns.color_palette("colorblind")
dict_colors = {
'line-search': 'Greens',
'gradient-descent': 'Purples',
'adam': 'Reds'}
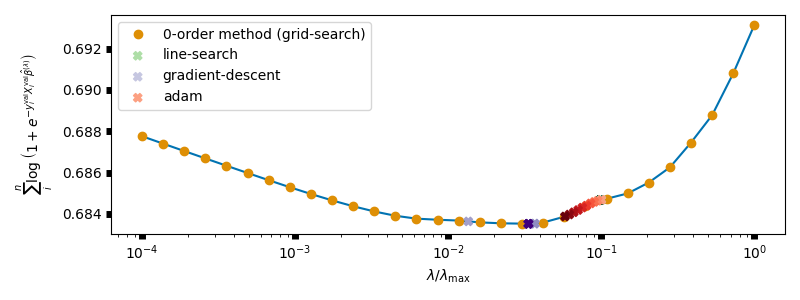
fig, ax = plt.subplots(figsize=(8, 3))
ax.plot(alphas / alphas[0], objs, color=current_palette[0])
ax.plot(
alphas / alphas[0], objs, 'bo',
label='0-order method (grid-search)', color=current_palette[1])
for optimizer_name in optimizer_names:
monitor = monitors[optimizer_name]
p_alphas_grad = np.array(monitor.alphas) / alpha_max
objs_grad = np.array(monitor.objs)
cmap = discrete_cmap(len(p_alphas_grad), dict_colors[optimizer_name])
ax.scatter(
p_alphas_grad, objs_grad, label=optimizer_name,
marker='X', color=cmap(np.linspace(0, 1, 10)), zorder=10)
ax.set_xlabel(r"$\lambda / \lambda_{\max}$")
ax.set_ylabel(
r"$ \sum_i^n \log \left ( 1 + e^{-y_i^{\rm{val}} X_i^{\rm{val}} "
r"\hat \beta^{(\lambda)} } \right ) $")
ax.set_xscale("log")
plt.tick_params(width=5)
plt.legend()
plt.tight_layout()
plt.show(block=False)
Out:
/home/circleci/project/examples/plot_compare_optimizers.py:118: UserWarning: color is redundantly defined by the 'color' keyword argument and the fmt string "bo" (-> color='b'). The keyword argument will take precedence.
ax.plot(
Total running time of the script: ( 0 minutes 2.602 seconds)